LLMs with Hugging Face - Part 3: Models - Architecture
When writing this post I went down the rabbit hole of machine learning architecture. I wanted to get a basic understanding of the third line in the code below, which was introduced in the first post, does.
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = ["I really enjoy swimming!"]
tokens = tokenizer(sequence, return_tensors="pt")
output = model(**tokens)
predictions = torch.nn.functional.softmax(output.logits, dim=-1)
highest_probability = predictions[0].max().item()
highest_label = predictions[0].argmax().item()
print("Highest probability:", highest_probability, ", label:", model.config.id2label[highest_label])Now, of course, this is where the magic happens. So, it was to be expected that figuring out what this step is about would take more time than the others.
A model's architecture is a structured neural network, i.e., a set of layers and connections between these layers that transform input to output. The power of neural networks compared to the basic functions taught during high-school algebra is that it can store complex information and as we see now with the recent AI boom it can even recognize patterns. There have been a range of different neural network structures that have been used but the transformer model has been dominant for the last couple of years.
The transformer is the leading machine learning architecture for large language models and other foundational models. Below is a picture of this machine learning architecture (source). It consists of an encoder on the left and a decoder on the right. Furthermore, it uses attention mechanisms to focus on the most relevant parts of a given input. We go over these concepts below.
#/media/File:Transformer,_full_architecture.png){kind=link}
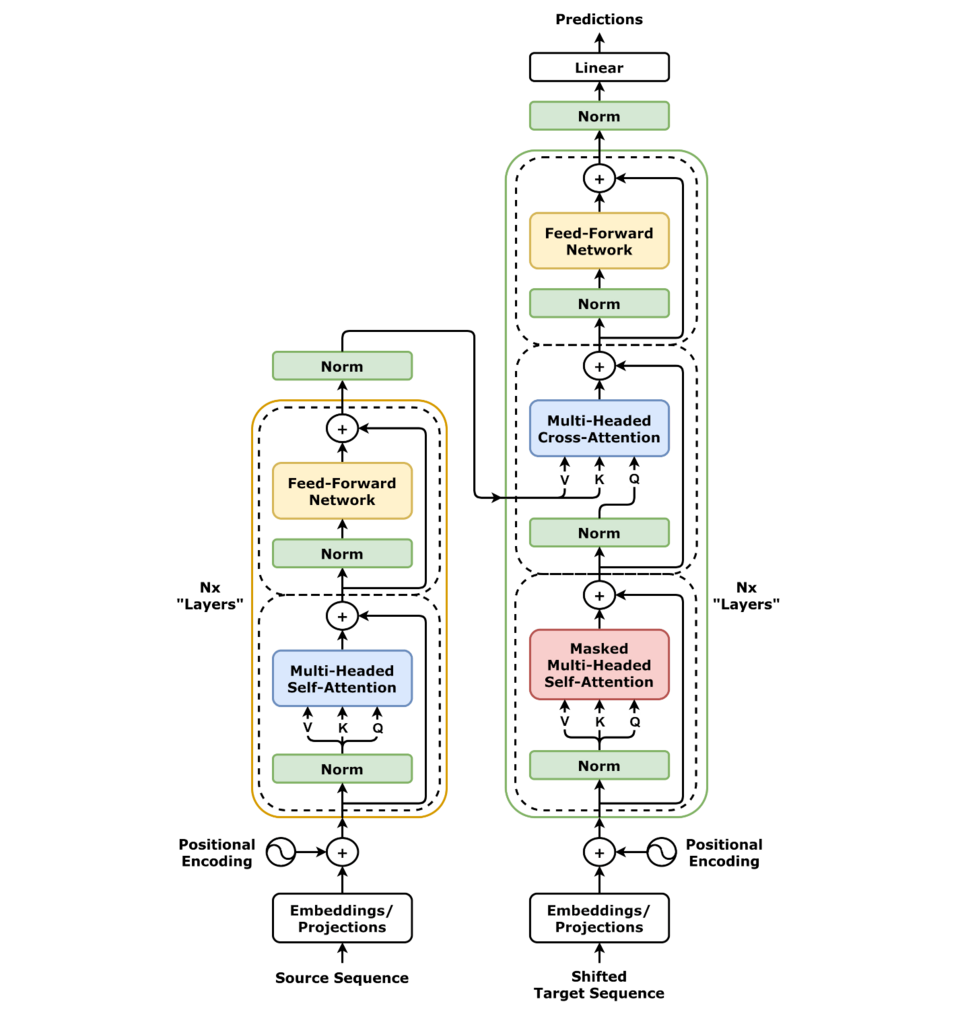
Attention is used by transformers to weight the importance of elements of a sequential input. To my current understanding, this means that if a couple of sentences of information are passed to a LLM and we query it for sentiment it will focus on the information that relates to sentiment, i.e., words like joy, fun, and hate. The initial paper that introduced transformers Attention Is All You Need showed that an architecture with only attention mechanisms outperforms architectures with recurrent and convolutional neural networks for translation tasks.
The encoder takes as input a sequence of tokens and transforms it to a new representation. The reason this is needed is the following. Each element in the input sequence only carries its own information. So, "I" in "I like swimming" does not say much without "like swimming". The encoder mixes this information and in that way gives extra context to each token. Encoders are, for instance, suited for tasks such as translation and sentiment-analysis. They take the meaning of a sentence and transform this to some desired output.
The decoder takes as input the output of the encoder, if present, and a prompt. It can keep generating text based on this prompt. Hence, when we use an LLM for next sequence prediction we need to use an LLM with a decoder.
A large range of transformer models are encoder or decoder only. An example of an encoder only model is BERT. This is the basis for the model we used in the example at the top of the page. It greatly outperformed existing models in language understanding. However, BERT will not perform well on generating sequences of text that make sense. On the other hand, the OpenAI GPT series are decoder only models.
My favourite sources on the transformer architecture (so far):
- Neural networks a YouTube series by 3Blue1Brown that builds up from neural networks to an introduction to transformers and LLMs.
- The Annotated Transformer a variation of the paper that introduced the transformer with code that implements the discussed architecture.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding the paper that introduced BERT.
- BERT for Sequence Classification from Scratch — Code and Theory goes over the architecture of BERT at a more introductory level.